Abstract
Video large language models (Video LLMs) have recently achieved strong performance on tasks such as captioning, summarization, and question answering. Many models and training methods explicitly encourage continuity across events to enhance narrative coherence. While this improves fluency, it also introduces an inductive bias that prioritizes storyline consistency over strict grounding in visual evidence. We identify this bias, which we call narrative prior, as a key driver of two errors: hallucinations, where non-existent events are introduced or existing ones are misinterpreted, and omissions, where factual events are suppressed because they are misaligned with surrounding context. To systematically evaluate narrative prior–induced errors, we introduce NOAH, a large-scale benchmark that constructs composite videos by inserting clips from other sources into target videos. By varying semantic similarity and insertion position, our benchmark enables controlled and scalable analysis of narrative priors. We design one captioning task with tailored metrics and three QA tasks—Existence, Temporal, and Narrative—yielding more than 60K evaluation samples. Extensive experiments yield three key findings: (i) most Video LLMs exhibit hallucinations and omissions driven by narrative priors, (ii) the patterns of these errors vary across architectures and depend on event similarity and insertion position, and (iii) reliance on narrative priors intensifies under sampling with fewer frames, amplifying errors when event continuity is weak. We establish NOAH as the first standardized evaluation of narrative prior–induced hallucination and omission in Video LLMs, providing a foundation for developing more reliable and trustworthy models.
Dataset Construction
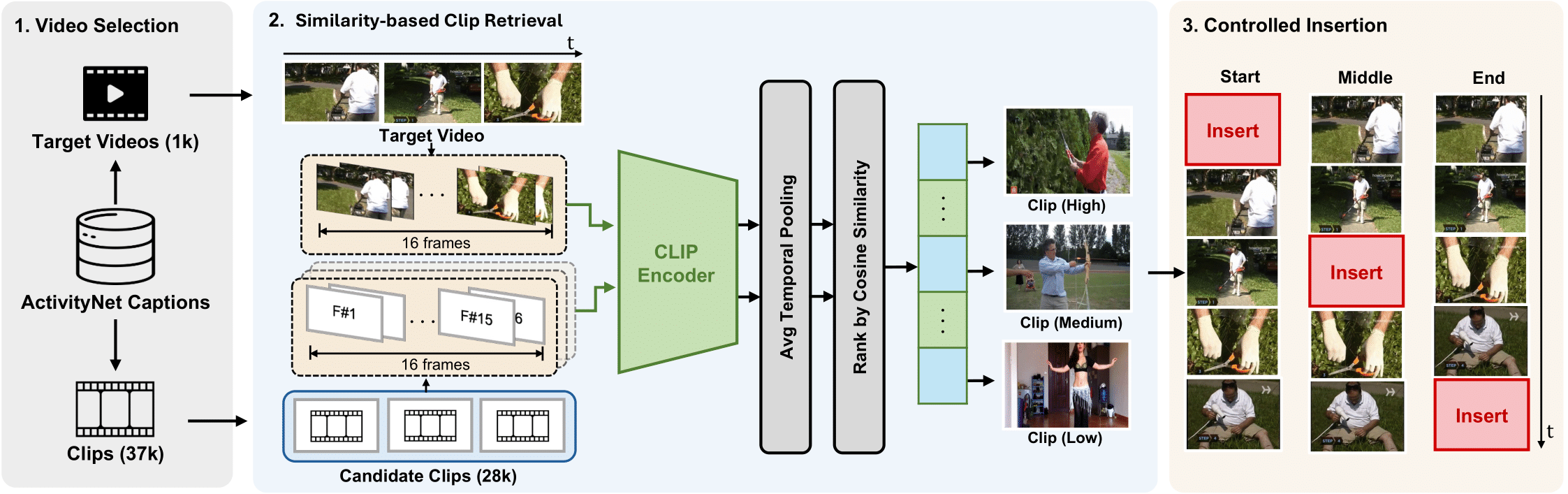
We construct composite videos to isolate errors driven by narrative priors. For each target video from ActivityNet-Captions, we insert an event-level clip from another video. Candidate clips are ranked by CLIP cosine similarity, and we select high, medium, and low similarity levels. Each clip is then inserted at the start, middle, or end of the target video, yielding 3×3 = 9 controlled variants per video. This design allows us to analyze how semantic plausibility and temporal context affect hallucination and omission. In total, we curate 1,000 target videos and construct 9,000 composite videos for systematic evaluation.
Data Statistics
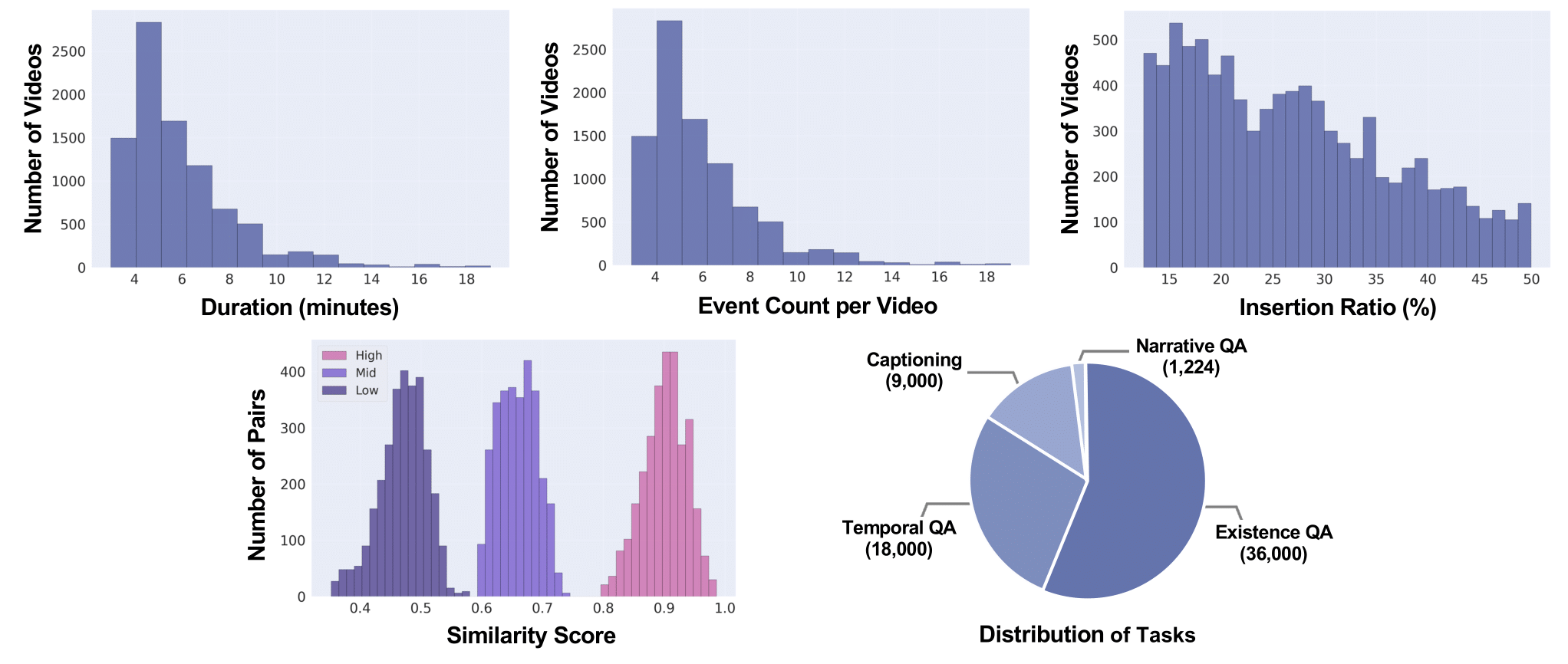
The NOAH dataset includes 1,000 target videos from ActivityNet-Captions and 9,000 composite videos evenly distributed across three insertion positions and three similarity levels. On average, the composite videos are 199 seconds long (ranging from 14 to 728 seconds) and contain 6.17 annotated events (range: 3–19). We provide distributions of video durations, event counts, similarity scores, and task samples. Unlike single-event QA benchmarks, NOAH enables controlled analysis of hallucination and omission in multi-event video settings.
Task

NOAH evaluates Video LLMs through one captioning task and three QA tasks. The captioning task measures whether models hallucinate unsupported events or omit factual ones when generating descriptions. Existence QA checks if a model can detect whether an inserted event is present in the video. Temporal QA tests whether the model can correctly identify the chronological order of the inserted event relative to its neighbors. Narrative QA probes a model’s ability to reject fabricated but plausible events that align with the surrounding storyline. Together, these tasks provide a comprehensive framework to analyze how narrative priors drive hallucinations and omissions in both open-ended and structured settings.
Experiments
Overall Results
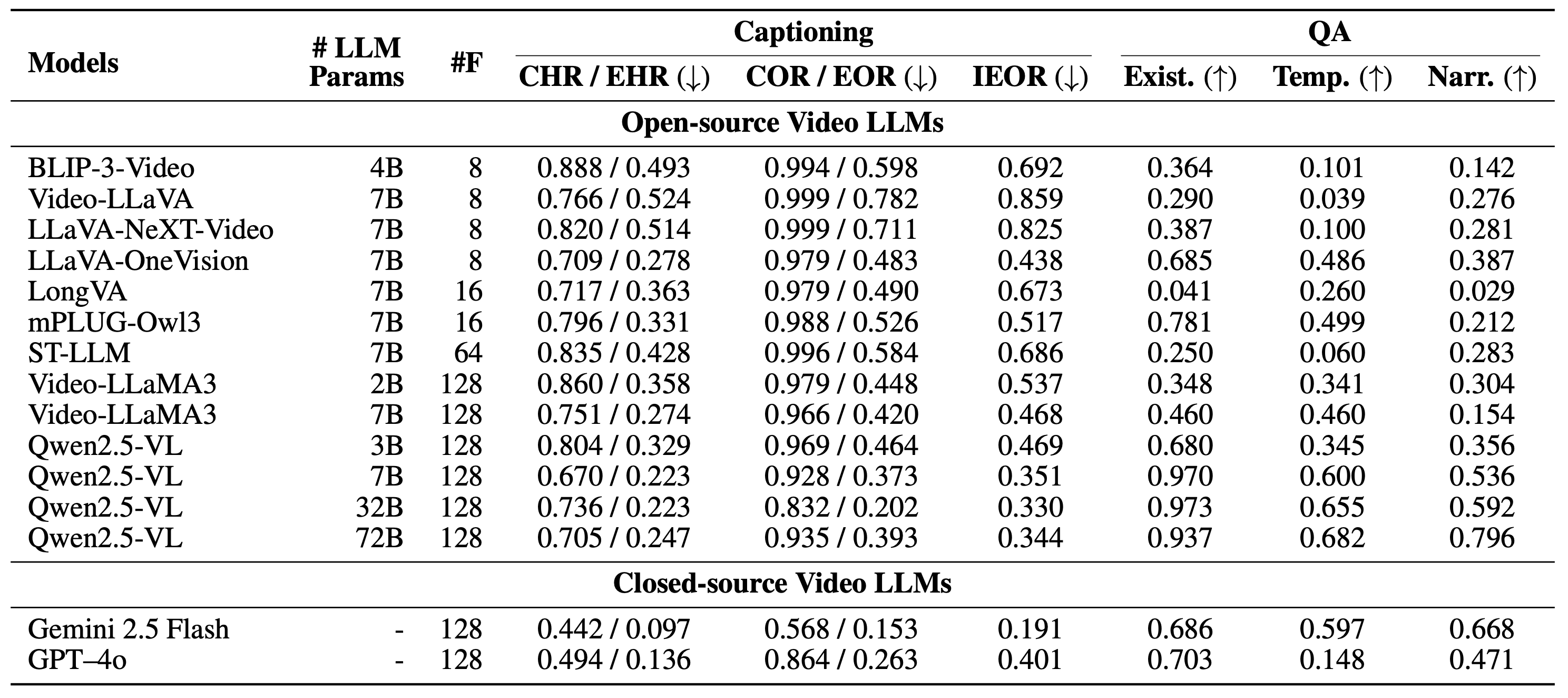
We evaluate a wide range of open- and closed-source Video LLMs on NOAH. Results show that most models frequently hallucinate or omit events, confirming that narrative priors strongly influence both captioning and QA tasks.
Controlled Evaluation
To isolate the effect of event insertion, we compare models on original videos, inserted clips, and composite videos. The results reveal that inserted events often trigger hallucinations and that models tend to ignore inserted content to maintain narrative coherence.

Analysis
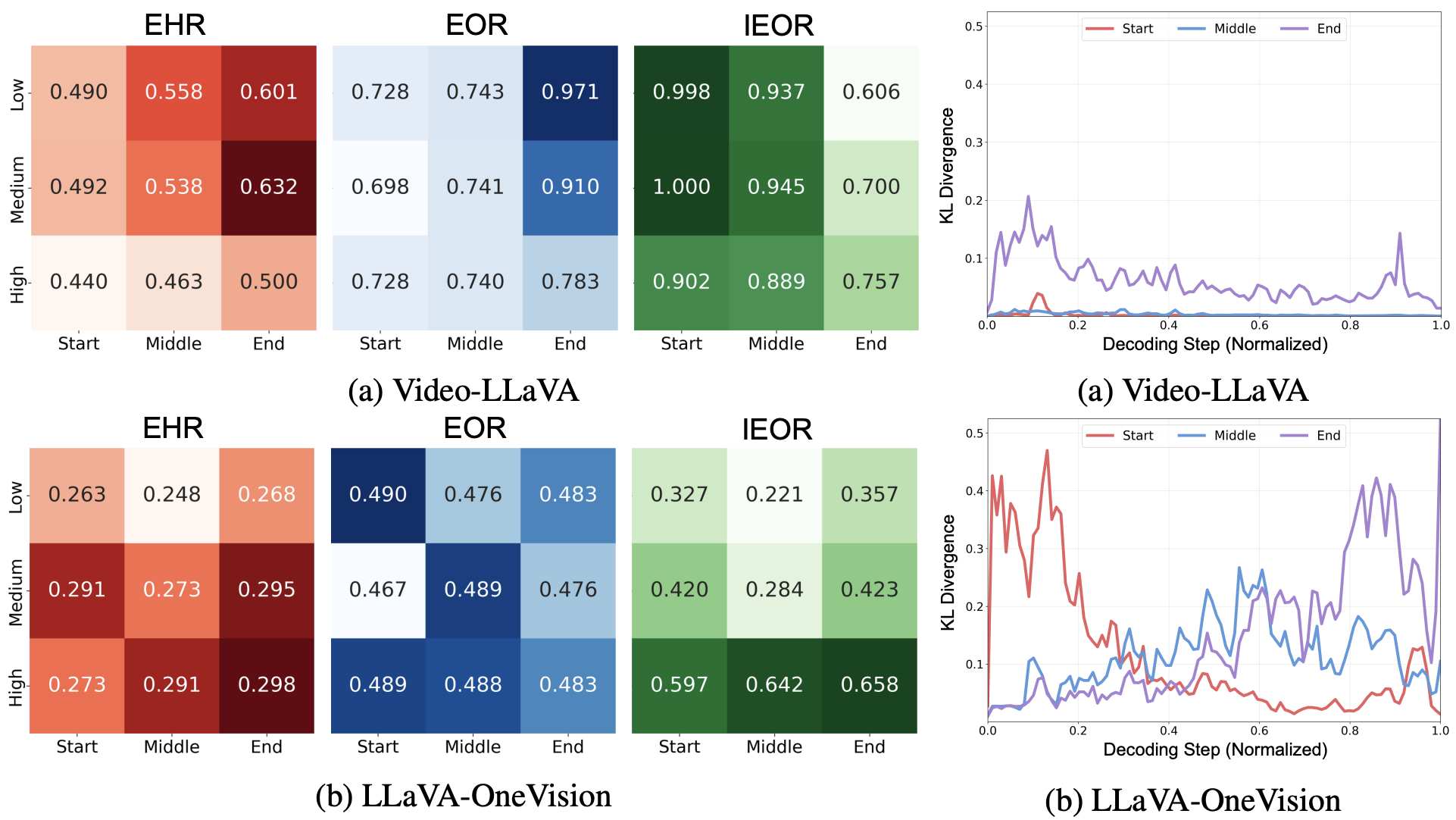
We conduct empirical analysis to examine how narrative priors drive hallucinations and omissions under different conditions. Error rates vary with insertion position and semantic similarity, with end and high-similarity insertions showing stronger effects. KL divergence reveals that narrative priors influence the entire decoding process, and reduced temporal context further amplifies these errors.